
Introduction
Large Language Models (LLMs) have triggered a massive transformation in the field of Artificial Intelligence, making it possible to produce texts that closely resemble human writing. Unlike older, less flexible models, these models can process vast amounts of data and are used in a variety of fields, including content generation, chatbot development, and programming automation.
What are Text Generation Models?
Text generation models are advanced artificial intelligence systems designed to understand and produce text. Their primary function is based on breaking down text into basic units called tokens. These tokens can include complete words, subwords, or even individual characters. Understanding the number of tokens in a text is crucial for managing processing limitations, as different models have varying token capacities.
Tokenization
One of the crucial preprocessing steps in these models is tokenization, which divides the text into smaller pieces to make processing more efficient. The most common tokenization methods include:
- Byte-Pair Encoding (BPE):
Gradually combines frequently occurring characters to create new tokens. - WordPiece:
Similar to BPE but optimized to reduce unnecessary breaking of rare words. - SentencePiece:
Efficient for languages that do not use space between words.
For example, in the BPE method, the word “hello” is initially seen as h, e, l, l, o, but after repeated processing, the frequent combination he is considered a single token, which increases the model’s efficiency.
The Mathematical Foundations of LLMs
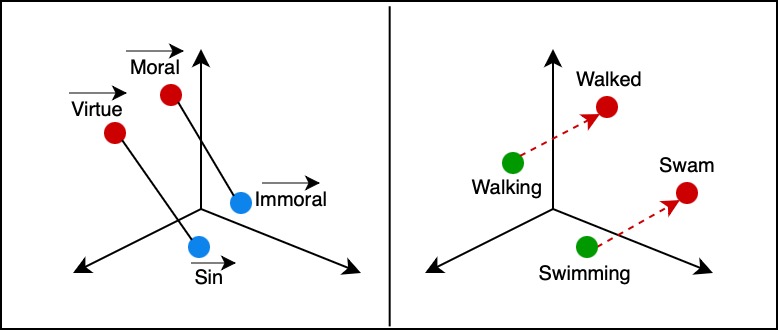
Large language models do not simply treat words as strings of letters; instead, they convert them into multi-dimensional numerical vectors known as word embeddings. This method allows words with similar meanings, such as ethics and virtue, to be placed close to each other in the vector space. This structure helps models better understand the relationships between words, language syntax, and semantic context.
The Transformer Architecture
The Processing Engine of Large Language Models
The key innovation behind modern language models is the transformer architecture, first introduced in Google’s famous paper Attention is All You Need in 2017. Unlike older models that processed text sequentially, transformers use a self-attention mechanism to process all the words in a sentence simultaneously.
For example, in the sentence The cat sat on the mat, the transformer model understands that cat is related to sat without needing to examine the words in order. This capability improves the model’s understanding of language and the relationships between words.
How Large Language Models Generate Text
After understanding the input, the large language model predicts the next word based on its probability of occurrence. These models assign a probability value to each possible word and select the option with the highest probability. This process is repeated for each new word to produce coherent and meaningful text.
Historical Development in the Transformer Architecture
Before the advent of the transformer architecture, language models like Recurrent Neural Networks (RNNs) and Long Short-Term Memory (LSTMs) faced many challenges, including:
- Inefficient Sequential Processing:
These models processed text word by word, making it difficult to learn long-term dependencies. - The Vanishing Gradient Problem:
Older models had trouble retaining information from the beginning of the text. - Low Efficiency at Large Scales:
Sequential processing increased computational time and cost.
The introduction of the self-attention mechanism allowed models to better understand long-range dependencies and enabled parallel processing, which significantly increased efficiency.
Computational Costs and Hardware Advancements
Training large language models requires enormous computational resources, which typically utilize specialized hardware:
- Graphics Processing Units (GPUs):
Optimize matrix processing, which is essential in deep learning. - Tensor Processing Units (TPUs)
Google’s custom-designed chips for AI-related processing. - Supercomputers and High-Performance Computing Centers(HPC):
Used for training very large models.
For example, training GPT-4 involved approximately 1.7 trillion parameters, and its computational cost reached $63 million. This intense need for computation has led to fierce competition among hardware companies, particularly NVIDIA, which dominates the advanced GPU market.
Conclusion and the Future of LLMs
The evolution of language models from older architectures to today’s complex systems demonstrates significant progress in artificial intelligence. New models not only have better understanding of language but also encompass multimodal capabilities (text, image, audio). The future of these models include:
- Improved accuracy and reduced linguistic errors.
- More optimized models for running on personal devices.
- Increased role of artificial intelligence in natural language processing (NLP) in specialized fields such as medicine and law.
Source: Prompt Engineering for Generative AI by James Phoenix, Mike Taylor